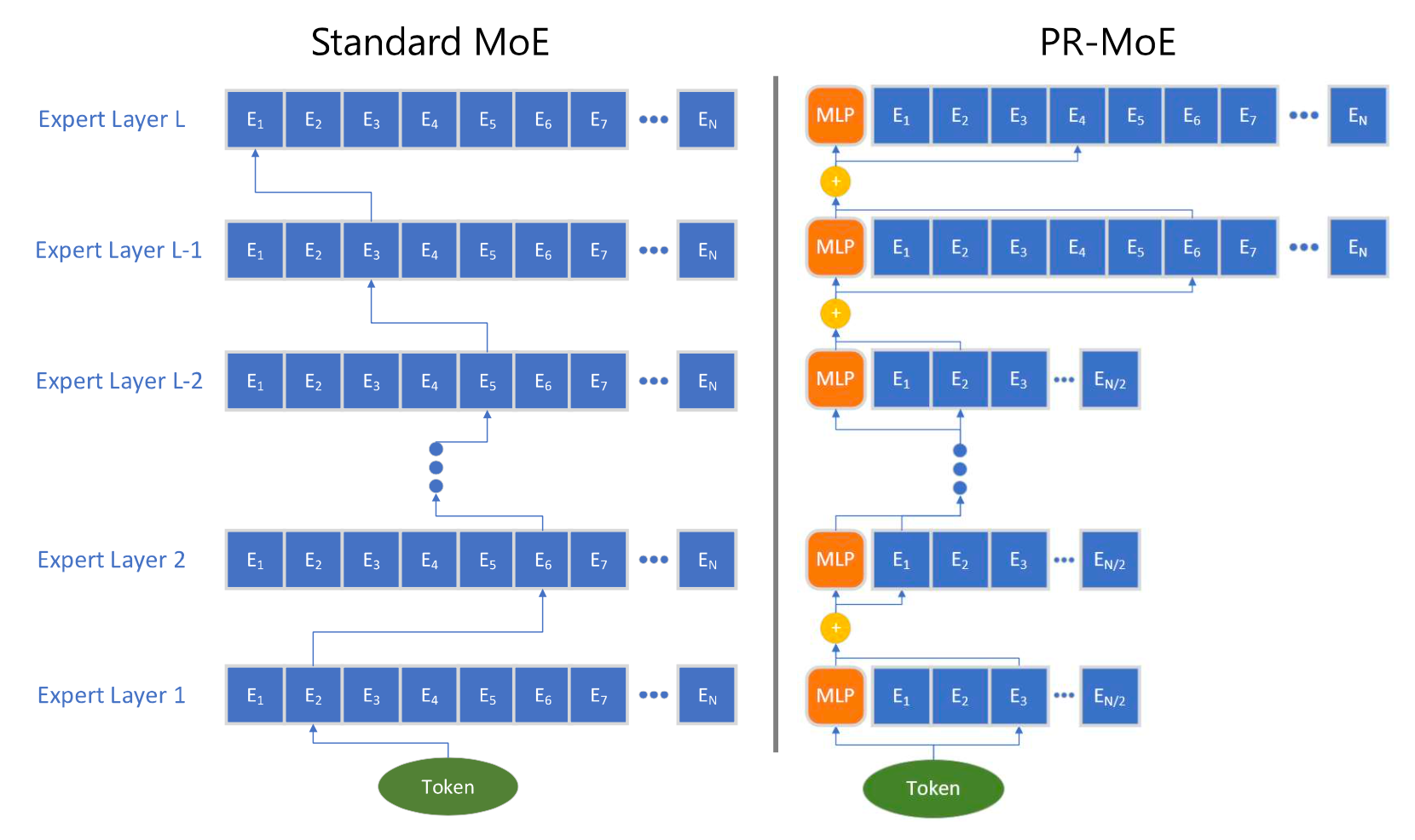
BERT-Large: Prune Once for DistilBERT Inference Performance
$ 22.00
4.6 (534) In stock