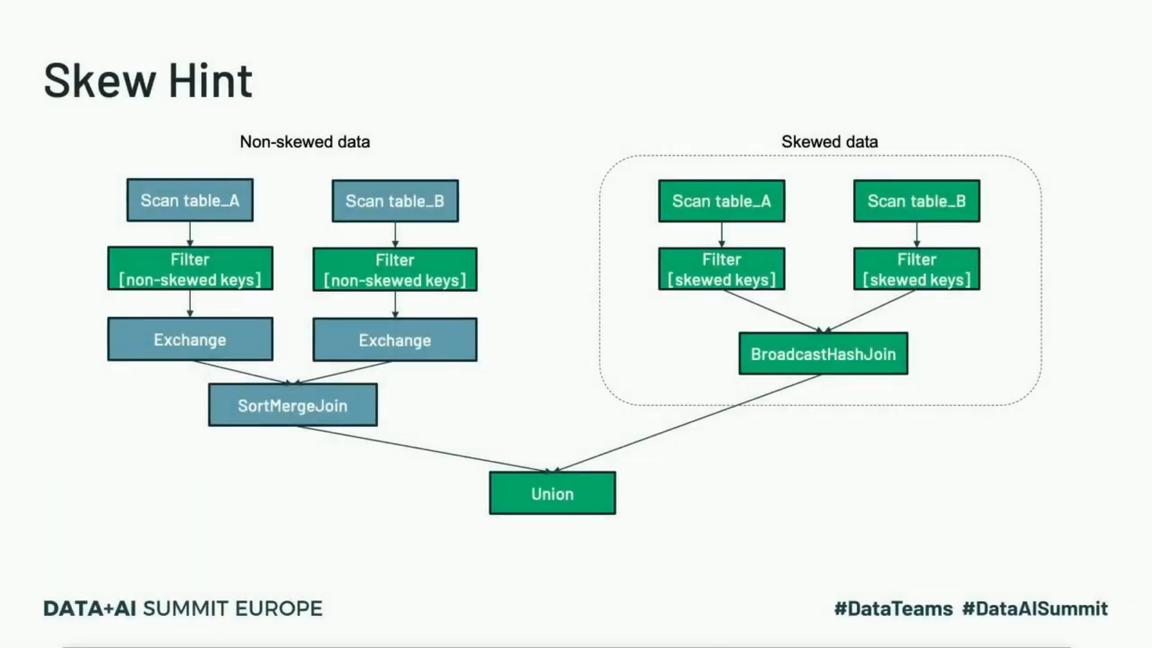
Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering
$ 8.99
4.9(631)In stock
In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…
Apache Kafka With Spark Structured Streaming With Emma Liu, Nitin Saksena, Ram Dhakne, Current 2022
Optimization of Spark Data Skew in Big Data Environment
The Data Engineers Guide to Apache Spark - The Data Engineer's Guide to Apache Spark has seen - Studocu
New Optimization Technique in Spark 3.0
Business Intelligence Career Master Plan Launch, PDF, Business Intelligence
Spark Performance Tuning: Skewness Part 2, by Wasurat Soontronchai
Performance optimization lessons from Spark+AI and Data+AI Summits on - articles about Apache Spark
PDF) Proceedings of 3rd International Conference on Emerging Technologies in Computer Science & Engineering ICETCSE 2016
Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering
Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering
Performance optimization lessons from Spark+AI and Data+AI Summits on - articles about Apache Spark